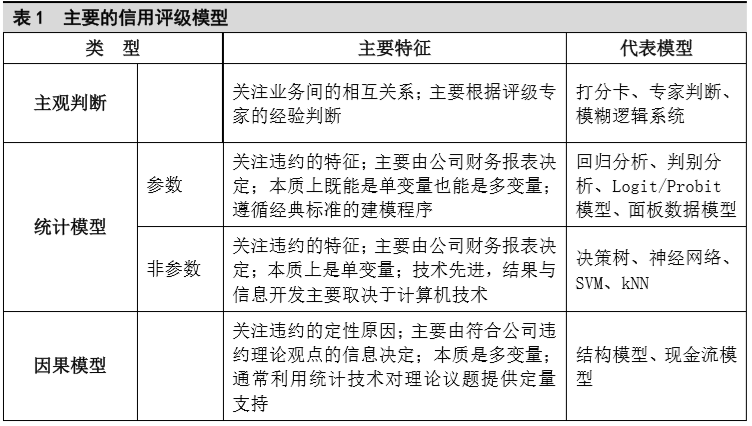
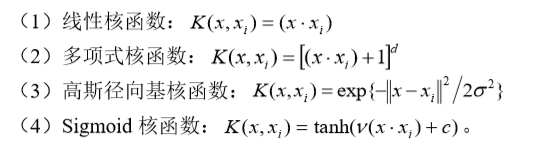其中f(x)为结果,  ,将输入向量映射到高维特征空间,使得特征向量之间的可区分性更强,然后在高维空间中求解最优分类超平面。求解非线性支持向量机,不论是寻优函数还是分类函数,均涉及样本之间的内积运算
,将输入向量映射到高维特征空间,使得特征向量之间的可区分性更强,然后在高维空间中求解最优分类超平面。求解非线性支持向量机,不论是寻优函数还是分类函数,均涉及样本之间的内积运算

(2)多项式核函数:
(4)Sigmoid核函数:  。
。
本文中将选择上面4个内核函数测试的评级模型,分别对不同信用分类数据集进行分类预测,展开实证分析,分类预测实验结果代表了分类预测模型的实际预测能力。
信用评估指标体系是信用评级工作的基础和依据,一套科学的指标体系是评估结果客观性、公正性和可信度的保证,也是智能评估模型效率及精度的保证。
(一)指标选择
在选择模型评估指标时,遵循重要性、全面性和弱相关性原则。本文根据行业特点,以专家经验判断、结合多次实验结果选出评估指标,未来拟将通过主成分分析等方法对评估指标进一步筛选。
本文以国内公开发债房地产企业为样本展开实证分析,且初衷是从公开财务数据测试分类准确性(隐含假设为财务数据已充分反映企业经营业绩),所以略去了企业经营数据和诸如领导人素质等其他指标。鉴于企业股权属性显著影响企业未来融资能力和发生危机时获得救助的可能性,在当期财务报表中无法充分体现,因此引入企业属性指标,该指标以打分形式进行赋值,打分范围为1~10。
房地产行业是一个风险较高的行业,具有周期性、资本密集型、投机需求旺盛、政策敏感度高、地域性明显等行业特点。指标体系主要考虑公司规模、营运能力、盈利能力、偿债能力和成长能力五个方面,评级模型指标体系见表2。
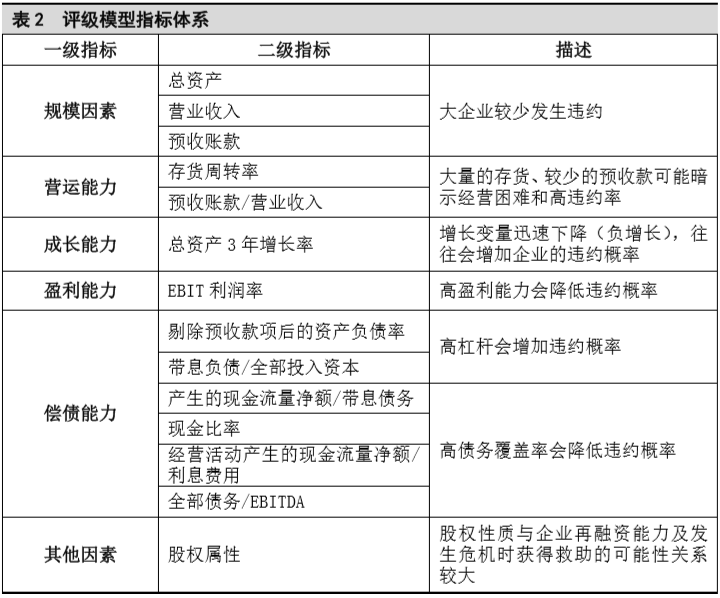
模型类标签为信用级别,映射为数值形式,本文采用作者所在机构内部评级结果,房地产企业内部最高级别为AA+,最低级别为BB。
(二)实验数据采集
本文采集了144家国内公开发债房地产企业2016年度上述指标数据,所有指标数据均来自Wind数据库,评级结果采用英大保险资产管理有限公司内部评级结果,其中BBB-~A+级样本数占比最大,共有99个。
(三)实验数据预处理
首先进行总体样本的筛选与抽样,并在建模之前将明显奇异的数据删除,最后剩余136个有效样本。
然后对数据进行归一化处理,本文采用线性归一化方法,数据归一化到(0,1)。数据进行归一化非常重要,文[9]解释了对神经网络的输入进行归一化的原因,对SVM来说基本相似。归一化最大的好处就是消除了量纲的影响。未归一化时,数值取值较大的指标会削弱取值较小的指标对模型的影响;其次,SVM需要计算样本点的内积核函数,未归一化时,过大的数值会引起数值计算上的麻烦。
五、实证分析
(一)实验流程
1.使用经归一化的数据构建4分类训练数据集和预测数据集(分类为AA、A、BBB、BB,标签映射为1、2、3、4)和8分类训练数据集和预测数据集(分类为AA+、AA、AA-、A+、A、A-、BBB、BB,标签映射为1、2、3、4、5、6、7、8);数据集均为随机分布,4分类和8分类训练数据集均为总体数据集前76个数据,预测数据集均为总体数据集后60个数据。
2.选择不同核函数和相应参数,使用svm-srtain.exe对4分类支持向量机进行训练,得到训练模型;
3.运用上述模型,使用svm-predict.exe对4分类预测数据集进行分类预测,分类预测实验结果代表了分类预测模型的实际预测能力;
4.对上述实验结果评价、比较后选出效果最优核函数,对8分类支持向量机进行训练,比较不同分类数下模型预测能力。
本文使用台湾大学林智仁博士开发的通用的支持向量机模式识别与回归的软件包(libsvm),在软件MATLAB中通过混合编译实现多分类实验过程。SVM其产生是为2分类问题设计的,libsvm采用one-versus-one法,在任意两类样本之间设计一个SVM,通过投票实现多分类。
(二)4分类实验结果
选择libsvm的不同核函数及有关参数,进行多次实验,取得局部最优预测效果时实验结果见表3。
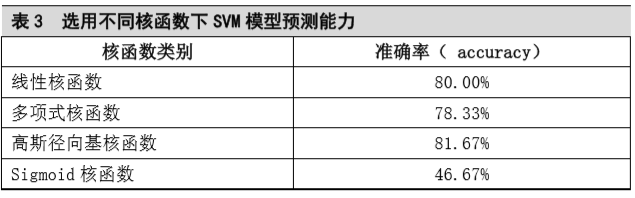
实验结果显示,选择线性核函数、多项式核函数和高斯径向基核函数分类模型均具有较高预测能力,而Sigmoid核函数分类模型预测效果较差,其中选用高斯径向基核函数时模型分类准确率最高,达到81.66%。
下面进一步对高斯径向基核函数实验进行参数寻优。上面实验中处罚参数c和自带参数g是经验值,可以对c和g值选取由程序多次迭代自动选出,选出的依据是令预测精确度最高时的最优值,参数取值如图1。
经参数寻优后,最终得到c为4,g为2,参数优化前后高斯径向基核函数实验结果如表4。

实验结果显示,参数寻优后高斯径向基核函数SVM模型预测准确率进一步提高,达到83.33%,通过分析实验输出结果中的预测标签发现错分类偏离度也较小。
(三)8分类实验结果
由以上实验可知,选择高斯径向基核函数时SVM模型多分类效果最好,下面仍选用高斯径向基核函数对8分类支持向量机进行训练,其中对c和g值选取仍由程序多次迭代自动选出,实验结果见表5。

从实验结果来看,随着分类数增加,模型预测准确率有所下降,但接近70%正确率仍具有一定实际意义。从预测结果分析,高评级样本过少导致模型欠学习,预测偏差较多,通过分析输出结果中预测标签发现错分类偏离度也较大。
六、结论与展望
信用风险定价能力逐渐成为资产管理机构一项核心竞争力,传统信用评级模型随意性和主观性等缺陷已对评估能力提升形成限制,本文尝试建立基于支持向量机的评级模型,并运用公开数据和机构内部评级结果进行实证验证。研究结果证明,支持向量机凭借坚实的统计学习理论基础,具有较强的逼近能力和泛化能力。支持向量机不仅具有与神经网络类似的不断学习、不断训练的功能,而且解决了神经网络难以避免的大样本、网络结构优化以及局部最优等问题[10]。从实验结果来看,在宽泛分类、快速级别估计方面,基于支持向量机的评级模型已具有较好的实用价值。当然,模型仍有很大改进空间,如在指标选取方法、SVM算法等方面可以进一步优化,也可与决策树、kNN等建立混合模型,进而开发更完善的人工智能评级系统,逐渐使其发展成为机构内部评级的重要工具。
参考文献
[1] 詹原瑞著,银行内部评级方法与实践[M],北京:中国金融出版社,2009
[2] Greene W, Econometric analysis[M], 5th ed, Prentice-Hall New Jersey, 2003
[3] Sohn, S.Y., Moon, T.H., Kim, S.H.Improved Technology Scoring Model for Credit Guarantee Fund[J]. Expert Systems with Applications,2005,28.
[4] 张鸿,丁以中,基于BP神经网络的企业信用评级模型[J],上海海事大学学报,2007,(3)
[5] Friedman C, Credit Model technical white paper, Standard Poor’s, 2002
[6] 陈伟,王业球,基于支持向量机方法的中小企业信用评级优化研究[J],云南财经大学学报:社会科学版,2011,(6)
[7] 朱顺泉,信用评级理论、方法、模型与应用研究[M],北京:科学出版社,2012
[8] 克里斯特安尼著,支持向量机导论(李国正,王猛,曾华军译)[M],2004,北京:电子工业出版社
[9] Sarle, W. S.. Neural Network FAQ [EB/O1 ]. http://www.informatik.uru-freiburg.de/}heinz/FAQ.html
[10] 张红,高帅,张洋,基于主成分分析和支持向量机的企业盈利能力预测[J],统计与决策2016,(23)