债券发行人信用风险识别研究——基于Logistic回归模型
A Study of Bond Issuer’s Credit Risk Identification —— Based on The Logistic Regression Model
文·谢首鹏 上海联合信用管理有限公司评级部副经理
摘要:
自2014年首支公募债违约以来,我国债券市场违约事件频发,近年来违约主体数和违约金额快速上升。尽管各大债券评级机构会对发行人主体和债券情况进行跟踪,并结合宏观经济环境和发行人财务状况对主体和债券级别作出跟踪评定,但这种跟踪评定往往具有滞后性,尤其体现在发行人爆出相关风险事件后评级机构才作出级别上的大幅度下调。同时,由于国内债券发行制度上的原因,加上评级技术和评级方法不够成熟,国内债券主体级别和债券级别存在虚高的现象,不能准确地揭示出其信用风险水平。本文运用债券发行人财务指标,对主体级别在AA及以上和AA以下债券发行人在各财务指标上的差异性进行了显著性检验,并基于Logistic回归模型建立了相关的统计模型,并尝试对上述两类债券发行人的信用风险情况进行度量。
“在终极的分析中,一切知识皆为历史;在抽象的意义下,一切科学皆为数学;在理性的世界里,所有判断皆为统计。”
——C. R. Rao,《统计与真理》
一、 研究背景
自从2014年3月首只公募债券“11超日债”违约,打破债券市场长期维持的“刚性兑付”神话以来,近三年国内债券市场违约事件频发。2015年违约债券数量从2014年的6只增至23只,违约金额也从13.40亿元大幅攀升至126.00亿元。据Wind资讯统计,截至2016年12月31日,2016年全年违约债券共计79只,涉及违约主体34个,违约金额合计403.00亿元。而根据联合资信的报告,2015年我国公募债券市场违约率为0.10%,2016年则上升至0.52%。从违约主体级别统计来看,2015年AA+级、AA-级和A+级违约率分别为0.17%、0.52%和1.47%,BBB级、BBB-和BB级违约率分别为4.11%、4.08%和6.67%,B-级和CC级违约率分别为33.33%和25.00%;2016年AA+级、AA级和AA-级违约率分别是0.29%、0.29%和0.65%,A级违约率为15.79%,BBB级和BBB-级违约率分别为4.35%和7.69%,BB级和BB-级违约率分别为5.88%和25.00%,B-级和C级违约率分别为100.00%和20.00%。从违约率的级别分布来看,与国际评级机构公布的违约率相比,我国各级别债券违约率普遍偏高,尤其主体信用级别AA级以下债券存在较大违约风险。显然,该类债券的识别,在规避债券违约风险方面,有利于增强债券投资安全边际,构筑厚实的风险缓冲区间,对于投资机构而言意义重大。
2017年将有约5.50万亿元规模主要信用债到期,在我国宏观经济仍然面临较大下行压力的情况下,加上宏观经济政策有所收紧,部分行业的信用风险将进一步暴露,信用等级的调整或将更趋频繁,违约事件将日趋常态化。对于银行、证券、基金、保险等债券投资机构而言,如何准确、及时地识别债券发行人主体级别,甄别高风险债券,规避违约损失,正成为越来越迫切的问题。
二、 研究目的
造成债券发行人主体信用等级变动的潜在因数有很多,宏观经济环境、行业景气程度、公司自身财务状况以及其他不可抗的因素等等,均有可能对债券主体的信用等级造成影响,从而引起信用风险的变化。本文旨在通过债券发行人主体的财务指标以及相关发债信息,对其主体信用度等级是否达到AA及以上等级进行识别。本文分析所用的数据集来自Wind资讯终端,包含2015年末市场上的15638只债券,经过财务指标去重处理和对缺失值进行多重随机插补后,剩余3409只债券(发行主体)信息。本文选取的潜在影响因素主要为债券发行人的相关财务指标,包括资产结构、偿债能力、经营效益和经营能力等方面,同时也包含了部分债券发行信息,共计45个变量(含债券名称),删除部分非必要变量后,剩余37个自变量,前36个为自变量(Xi),最后一个为因变量(Y,发行人最新评级)。具体如表1所示。
表1 数据集变量名称与符号对应情况

三、研究方法和工具
1.研究方法
当通过一系列的连续性和(或)类别型自变量来预测二值型因变量时,Logistic回归模型是一种非常有用的方法。该方法的最大特点之一就是可以得到事件发生概率的显性表达。模型假设因变量Y服从二项分布,模型的基本表达形式如下:
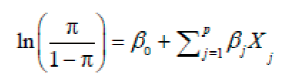
其中π表示给定一系列X时Y=1的概率,即一定条件下事件发生的概率,π/(1-π)为Y=1时的优势比,ln(π/(1-π))表示对数优势比,是Logistic回归模型的链接函数,等式右边表示各个自变量的和,是一个多元线性方程。
Logistic回归模型属于广义线性模型(GLM),实际上是线性模型的一种推广,常用于二值型结果的统计建模,在医学、心理学、社会学、经济学等领域有着广泛的应用。本文研究问题是对债券发行人主体信用等级是否在AA及以上进行识别,因而选择该模型进行分析研究。
2.研究工具
本文研究工具为R。R是用于统计分析、建模和可视化的一整套语言和操作环境,是属于GNU系统的一个自由、免费的开源软件,是用于统计研究的优秀工具。相比其他流行的统计分析软件,如SAS、IBMSPSS、MATLAB、Stata及Minitab等,R拥有诸多值得推荐的特性。首先,多数商业软件价格不菲,但R是完全开源的,对财务状况平平的分析研究人员而言,其优势显而易见;其次,R是一个全面的统计研究平台,全球各地的统计学专家、学者,贡献了众多的安装包,用于解决统计、数学、经济、金融、医学、生物等诸多领域的相关问题,提供了各式各样的数据分析技术,几乎任何类型的数据分析工作皆可通过R完成;再次,R是一个交互式数据分析和探索的强大平台,任何一个分析步骤的结果均可以进行保存、操作;最后,囊括了各种统计分析方法,并且可拓展性非常强,操作灵活。
本文分析过程通过Rstudio进行实现,所用版本为R3.2.3,通过运行R语言程序,所有数据可视化、统计分析和建模过程均可重现。
四、统计建模
1.统计描述
如前所述,本文数据集中包含3409个样本,其中发行主体信用等级AA及以上级别的债券2973只,占比87.21%;AA以下级别的436只,占比12.79%。从是否为城投债角度看,非城投类2033个,占比59.64%,城投类1376个,占比40.36%。AA级以上主体中,非城投有1724个,城投债1249个;AA级以下债券中,非城投债有309个,城投债127个。不难看出,尽管城投债占总体比重超过40%,但AA级以下城投债占比为3.73%,低于非城投债的9.06%,可见城投类债券相对非城投类债券优质,这也是近年来城投类债券受到市场青睐的原因。具体情况如图1所示。
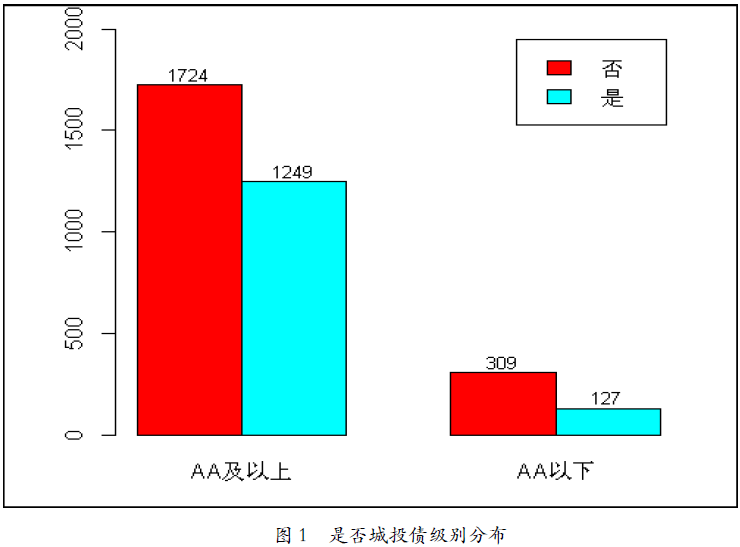
图1 是否城投债级别分布
从是否为上市公司角度看,非上市公司2645个,占比77.59%,上市公司764个,占比22.41%。AA级以上主体中,非上市公司2337个,上市公司636个;AA级以下债券中,二者分别为308和128个。可以看出,平均而言,上市公司在债券主体级别表现要逊色于非上市公司。具体情况如图2所示。
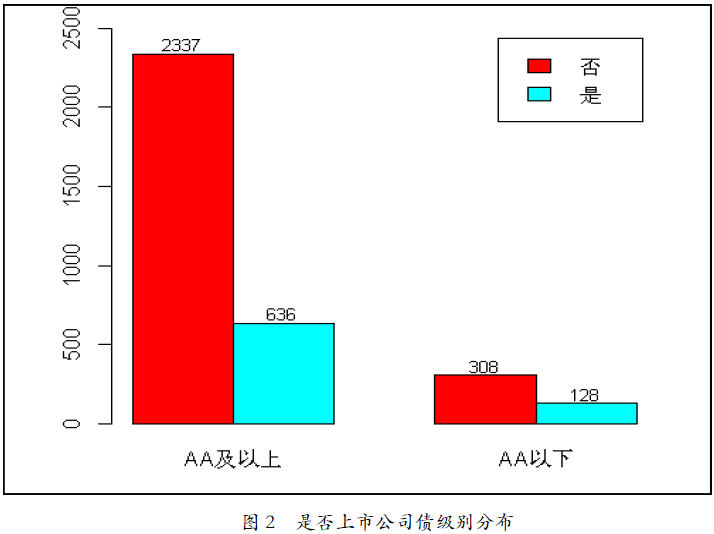
图2 是否上市公司债级别分布
从公司属性来看,3409个发行主体中,有2294个为地方国有企业,占比67.29%,其中AA及以上级别和AA以下级别个数分别为2050和244,相应占比为89.36%和10.64%;其次为民营企业,合计549个发行主体,AA及以上级别和AA以下级别个数分别为419和130,相应占比为76.32%和23.68%;再次为中央国有企业363个,AA及以上级别和AA以下级别个数分别为342和21,相应占比为94.21%和5.79%。不难看出,中央国有企业级别表现最好,其次为地方国企,民营企业表现则逊色于前两者(见图3)。

图3 不同属性发行人级别分布
2.相关性分析
在建立Logistic回归模型之前,我们尝试对33个财务指标两两之间的相关性进行分析,计算出528个(组合C(33,2))相关系数,并对其相关系数矩阵进行可视化。从图4中可以很直观地看出,大部分的财务指标之间相关性不强,且正相关关系多于、强于负相关关系,剔除因指标计算公式接近引起的数值较大的相关系数,我们可以发现X13和X27(总资产收益率和EBITDA/负债总额)相关系数为0.787,X29和X34(经营活动净现金流/带息债务和EBITDA/带息债务)相关系数为0.957;负相关关系方面,X20和X22(经营活动净现金流/流动负债和非筹资性净现金流/负债总额)相关系数为-0.591。财务指标间的相关系数矩阵可视化图如图4所示。
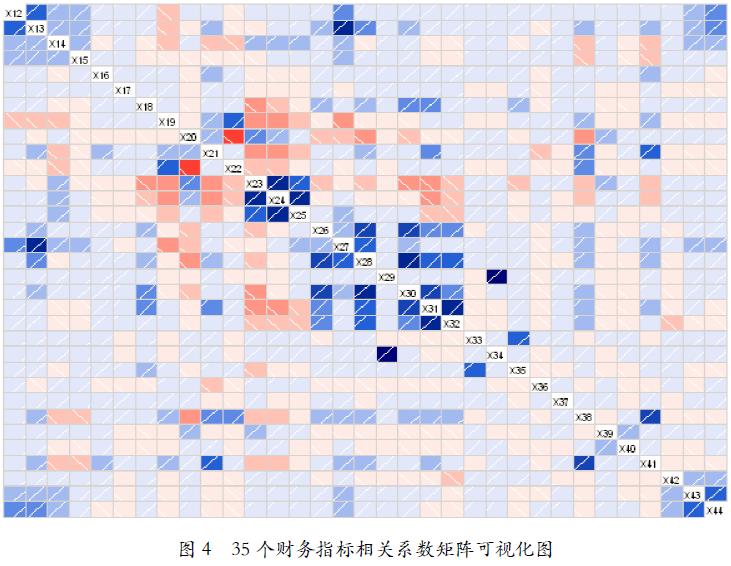
图4 35个财务指标相关系数矩阵可视化图
注:该图关于对角线对称,对角线上一次为财务指标X12-X44,蓝色小方格表示对应的相关系数为正,小方格内白色斜线也表示相关系数为正,方格颜色越深表示相关系数越接近1,越浅则表示越接近0;红色小方格表示相关系数为负,反斜线也表示相关系数为负,颜色越深表示相关系数越接近-1,越浅则表示越接近0。
3.显著性检验
对于AA及以上级别的发行人和AA以下级别发行人,很自然地,我们会关心的一个重要问题是,两种类型的发行人在财务表现上是否存在显著性差异,哪些财务指标差异显著,哪些差异不显著。本文采用Wilcoxon秩和检验对两种类型发行人的35个财务指标分别进行检验,并设定置信度为95%。在进行显著性检验之前,我们可以先分组计算一下33个财务指标的均值和标准差,如表2所示。从中不难看出,有些财务指标间的均值相差较大,如净资产收益率,AA及以上级别的发行人净资产收益率的平均值为4.41%,而AA以下级别发行人的平均值则为-3.37%;现金到期债务比,二者平均值分别为24.82%和-6.22%,说明级别高的发行人盈利能力和现金支付能力均比较强。有些财务指标的均值则相差较小,如销售毛利率,AA及以上级别的发行人销售毛利率的平均值为23.76%,而AA以下级别发行人的平均值则为22.93%,仅相差0.83个百分点;速动比率,二者平均值分别为1.45%和1.25%,相差0.2个百分点。
表2 33个财务指标的分组平均值和标准差
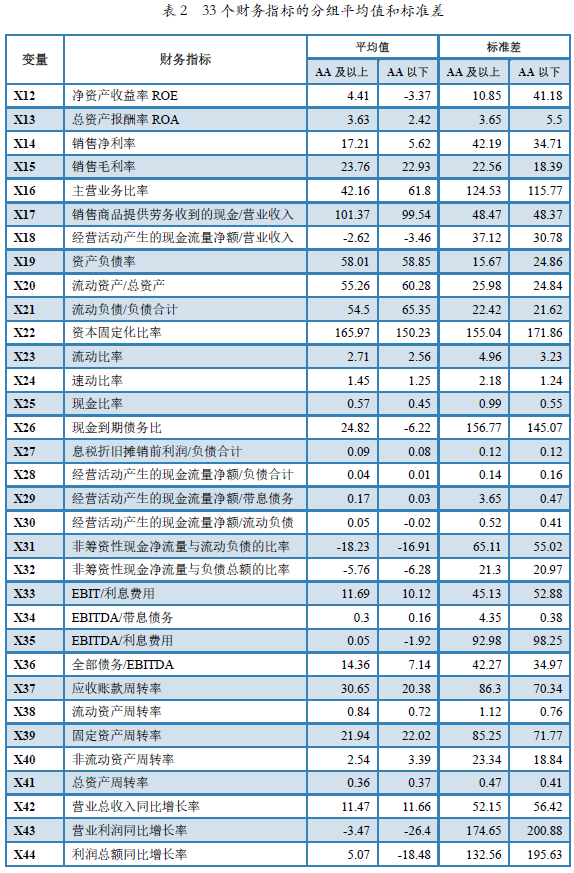
尽管从表2中可以看出某些财务指标的均值之间相差较大,有些相差较小,但差异是否显著须进行统计检验。从Wilcoxon检验结果来看,在95%置信度下,共有21个财务指标的P值小于等于0.05,且其中13个财务指标的P值等于0,说明两类发行人的上述财务指标差异非常显著;剩余12个财务指标的P值大于0.05,说明两类发行人在这12个财务指标上的差异不显著。具体情况如图5和图6所示。
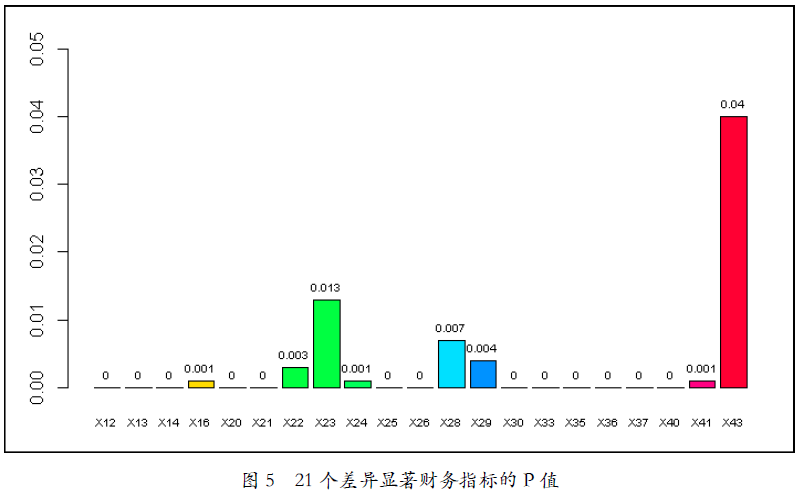
图5 21个差异显著财务指标的P值
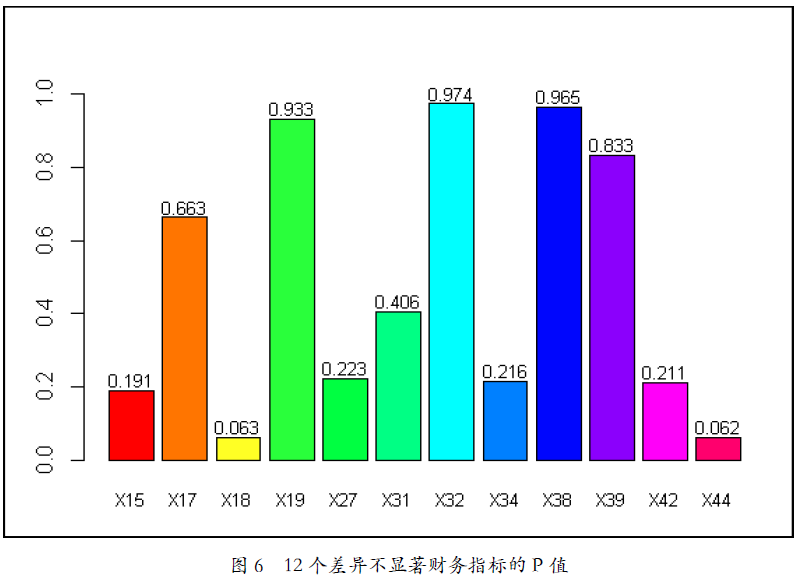
图6 12个差异不显著财务指标的P值
4.Logistic回归
通过逐步回归的方法对数据建立Logistic模型,我们可以得到因变量和各个自变量之间数量关系的线性表达,找出影响债券发行人信用等级的因素,从而建立起债券发行人信用等级的识别模型。更进一步地,我们可以运用模型得到每个发行人级别为AA以下的概率,找出最合适的阀值并作出预测,通过与实际情况对比可以得到模型预测的准确度,对模型预测效果进行评估。运用BIC准则,逐步回归进行变量筛选后,得到的回归模型参数估计结果如表3所示。
表3 BIC准则下逐步回归模型参数估计结果
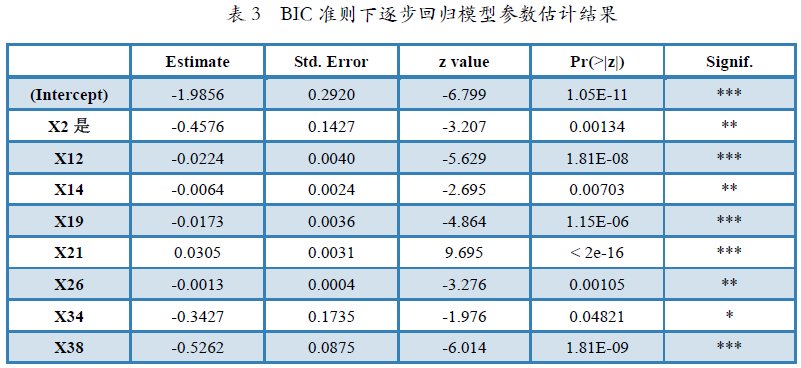
从表3中可以看到,最终的模型自变量个数从36个减少至8个,分别为X2(是否为城投债)、X12(净资产收益率)、X14(销售净利率),X19(资产负债率)、X21(流动负债/负债合计)、X26(现金到期债务比)、X34(EBITDA/带息债务)和X38(流动资产周转率),降维效果非常明显。同时,每个因变量(包含常数项)均非常显著,对应的参数估计结果分别为-1.9856、-0.4576、-0.0224、-0.0064、-0.0173、0.0305、-0.0013、-0.3427和-0.5262,正号说明对应自变量与因变量之间为正向关系,负号则为反向关系。此时对应的回归方程为ln(π/(1-π))= -1.9856-0.4576*X2-0.0224*X12-0.0064*X14-0.0173*X19+0.0305*X21-0.0013*X26-0.3427*X34-0.5262*X38,将方程右边记为f(xi),进一步可得到AA以下等级概率π的解析式为:
π = exp( f(xi) ) /( 1 + exp( f(xi) ) )
5.模型预测和准确度
通过Logistic回归建立模型后,我们可以对每个发行人债券的信用等级在AA以下的概率进行计算。首先,我们按照默认阀值(threshold)0.5进行划分,即预测概率大于等于0.5为AA以下,小于0.5为AA及以上,并得到对应的混淆矩阵(Confusion Matrix),如表4所示。
表4 未调参下的模型混淆矩阵(阀值0.5)

从混淆矩阵我们可以很容易计算得出,在0.5为阀值的情况下,模型对AA及以上发行人的级别预测准确率(特异度:specificity)为99.56%(2960/2973),AA以下发行人的级别预测准确率(灵敏度:sensitivity)仅为4.13%(18/418),整体预测准确率为87.36%。显然,模型在AA以下发行人级别的预测上效果很差,对于债券风险的识别而言并无太大现实意义。
为了提高灵敏度,即对AA以下发行人等级的预测准确率,我们可以对模型调参,设定最大化特异度和灵敏度的和(max(specificity + sensitivity))为目标函数,以此为条件选出“最优”的阀值。同时,我们设定误判AA以下级别和误判AA及以上级别的对价比(cost,风险厌恶水平)为10,因为如果模型将AA以下判定为AA及以上级别,发生误投可能带来违约损失,造成投资亏损;而将AA及以上判定为AA以下,不对该主体发行的债券投资,则避免了对应的损失。在设定了目标函数后,模型给出的阀值为0.1233,在此标准下,我们新得到的混淆矩阵如表5所示。
表5 调参后的模型混淆矩阵(阀值0.0241)
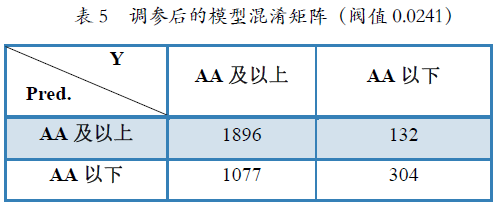
从新的混淆矩阵我们可以很容易计算得出,模型对AA及以上发行人的级别预测准确率为63.77%(1896/2973),AA以下发行人的级别预测准确率为69.72%(304/132),整体预测准确率为64.54%。此时,通过牺牲特异度,尽管整体预测准确率降至64.54%,但模型在AA以下发行人级别预测上的效果有了非常明显的提升。根据此模型,投资人面对市场上3409个发行主体,误踩AA及以下的概率为3.87%(132/3409),大幅低于平均情况下的12.79%(436/3409),该风险识别结果对于投资人而言具有明显的积极意义。
进一步地,我们考虑在投资人风险厌恶水平(cost)逐步提高的情况下,是否存在相应的某个阀值,通过逐步牺牲特异度使得灵敏度能够达到100%。不同风险厌恶水平下的模型迭代结果如表6所示。从迭代结果可以看出,随着风险厌恶水平的逐步升高,模型灵敏度逐步提升,阀值、特异度和整体预测准确率则逐步下降,当风险厌恶水平为50时,模型灵敏度提升至100%,此时对应的阀值为0.0148,对AA及以上级别预测准确率降至3.09%,整体预测准确率为15.49%。在此模型下,投资人可选择的投资目标(tn)为92个,另有2881(fp)个AA及以上发行人级别因判为AA以下,不在投资篮内,而准确判为AA以下的436(tp)个发行人也剔除在外。根据此模型进行债券投资决策,可大幅度减轻投资人对债券发行人的分析研究成本,同时可以有效避免对AA以下发行人的误投,从而规避违约损失风险。
表6 不同风险厌恶水平下的模型预测表现

进一步,为了了解调参后模型的稳定性,我们运用蒙特卡洛模拟中的自助法(bootstrap)对模型预测误差进行测算,模拟次数设定为2000次,结果如表7所示。从中可以看出,在阀值为0.0148的情况下,模型灵敏度95%置信区间为100%~100%,说明对AA以下发行人主体级别的预测效果非常稳定;模型整体预测准确率因对AA及以上发行人级别预测的变动,其置信区间为14.96%~16.08%。总体来看,调参优化后的模型表现明显更好。
表7 95%置信度下自助法模拟2000次的模型预测表现

6.区域风险、行业风险度量及其他
基于Logistic模型所得的回归方程,我们可以很容易得到每个发行人的信用等级在AA以下的概率值。根据每个发行人的省份、行业等分类信息,我们可以对概率值进行分类统计并计算其均值,作为分类情况下对债券发行人信用风险的一种描述,以此为基础构建出债券发行人的区域、行业等分类风险度量。
从区域风险分布情况可以看出,除港澳台三地外,全国31个省、直辖市中,债券发行人信用风险最高前5个地区依次是辽宁(0.176)、山西(0.150)、青海(0.149)、内蒙古(0.148)和黑龙江(0.145),风险最低的5个地区则依次是西藏(0.053)、广西(0.098)、宁夏(0.099)、海南(0.101)和陕西(0.105)。各个地区具体风险情况如表8所示和图7所示。
表8 全国各省份债券发行人信用风险情况
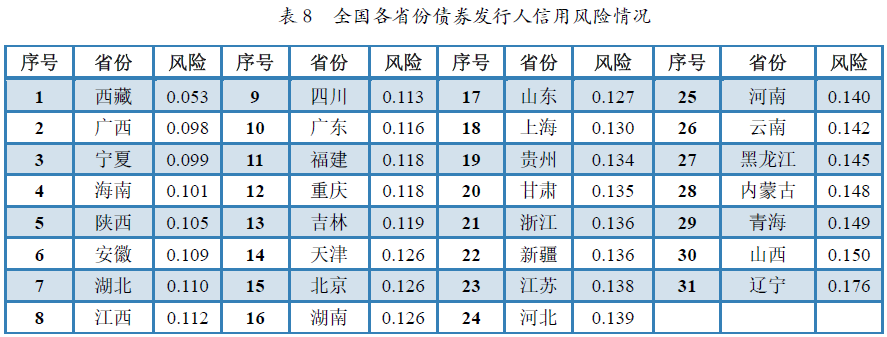
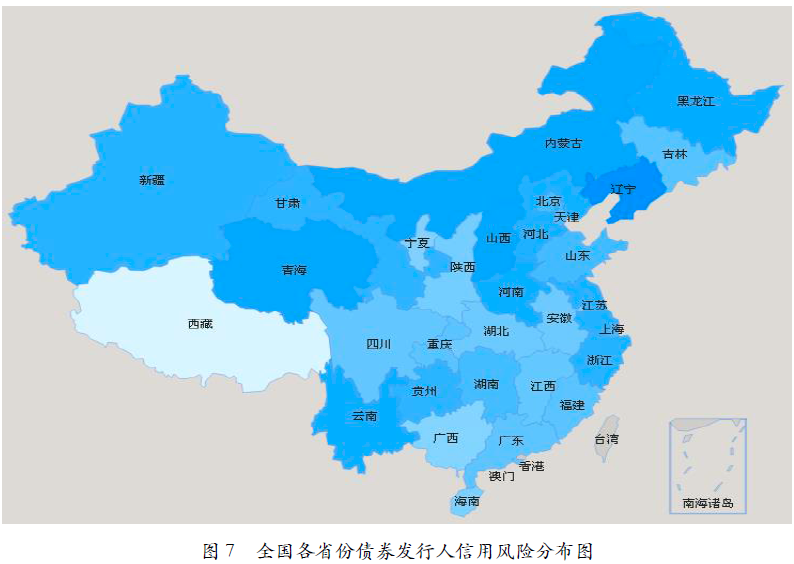
图7 全国各省份债券发行人信用风险分布图
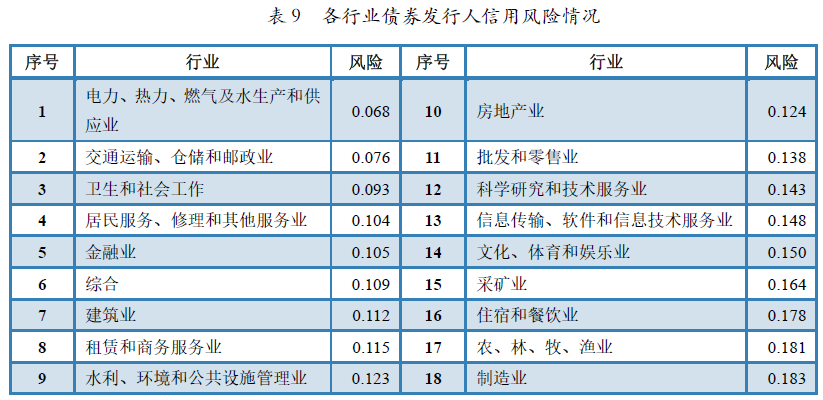
除了区域风险,我们也关心发行人的行业风险情况。从行业风险分布情况可以看出,债券发行人信用风险最高的前5个行业依次是制造业(0.183),农、林、牧渔业(0.181),住宿和餐饮业(0.178),采矿业(0.164),文化体育和娱乐业(0.150),风险最低的5个行业则依次是电力、热力、燃气及水生产和供应业(0.068),交通运输、仓储和邮政业(0.076),卫生和社会工作(0.093),居民服务、修理和其他服务业(0.104),金融业(0.105)。各个行业具体风险情况如表9所示。
表9 各行业债券发行人信用风险情况
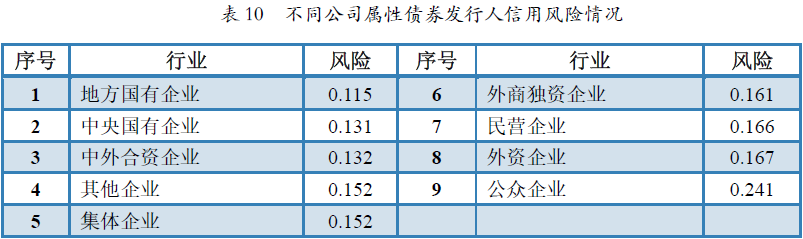
除了区域风险和行业风险度量,我们也可以按照发行人是否为城投债主体、是否为上市公司和发行人公司属性进行风险计算。根据计算结果,我们得到城投债发行主体的风险值为0.092,低于非城投债发行主体的风险值0.152,说明平均而言城投债信用风险低于非城投债。上市公司债券发行主体风险值为0.156,高于非上市公司发行主体的0.120,则说明平均意义下上市公司债券信用风险反而高于非上市公司。同时,我们可以看到,在不同公司属性下,平均而言地方国有企业的风险最低,为0.115,其次是中央国有企业(0.131);风险最高的为公众企业(0.241)和外资企业(0.167),具体情况如表10所示。
表10 不同公司属性债券发行人信用风险情况
五、总结
从上述统计建模过程和结果,我们可以得出以下几点结论:
第一,通过Wilcoxon秩和检验,我们可以看到,AA及以上级别发行人和AA以下级别发行人在33个财务指标中,有21个指标存在显著性差异,有12个指标的差异则不显著。
第二,通过BIC准则筛选后得到的模型,我们可以看到在该准则下,36个自变量中有8个变量得以保留,8个变量分别为X2(是否为城投债)、X12(净资产收益率)、X14(销售净利率),X19(资产负债率)、X21(流动负债/负债合计)、X26(现金到期债务比)、X34(EBITDA/带息债务)和X38(流动资产周转率)。
第三,通过对模型进行调参和优化,在确定目标函数的情况下,我们发现在设定风险厌恶水平为10时,模型在风险识别上已具有一定参考意义和实用价值,而随着投资人风险厌恶水平的提高,模型灵敏度可以不断提升,并最终达到100%,对应的模型有望为投资人进行债券投资决策及风险管理带来巨大帮助。
第四,通过模型的概率计算结果,我们按照省份、行业等信息对债券发行人的信用风险进行了分类计算和排名,所得的结果与现阶段债券市场的实际情况基本一致,具有较好的参考价值。
印度裔著名统计学家C.R.Rao在其著作《统计与真理》的扉页上说“在理性的世界里,所有判断皆为统计”,笔者深以为然。我们相信不远的未来,统计模型、机器学习和深度学习算法在大数据时代背景下,将在金融、交通、生物、医疗、互联网等社会经济的各个领域大放异彩,并有力地推动各行业的深刻变革。
